はじめに
Qlik Senseは、様々なデータベースに幅広く対応しており、社内の業務データから外部のオープンデータまで取り込んで分析することが可能です。具体的には、以下のようなデータソースが対象です。
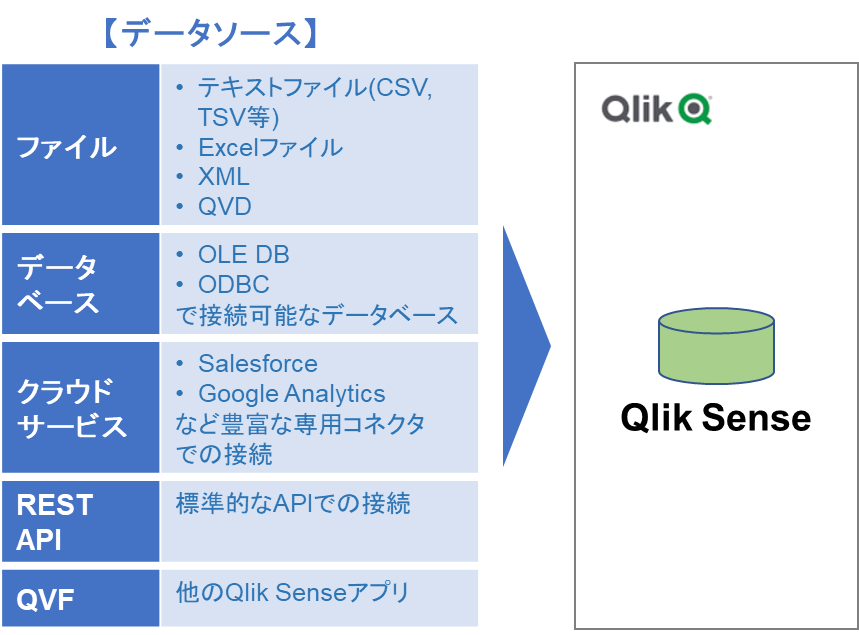
分析アプリにおけるデータの取り込みは、データマネージャー、又は、データロードエディタから行います。このうちデータロードエディタでは、幅広いデータソースからデータの抽出や複雑なデータ変換ができます。今回は、データロードエディタによる、Amazon S3からのデータ取り込みについて、紹介しようと思います。
Amazon S3からQlikへのデータ取り込み
Qlik senseとAmazon S3の接続については、データロードエディタを開いて、右側にある『接続の新規作成』から行います。
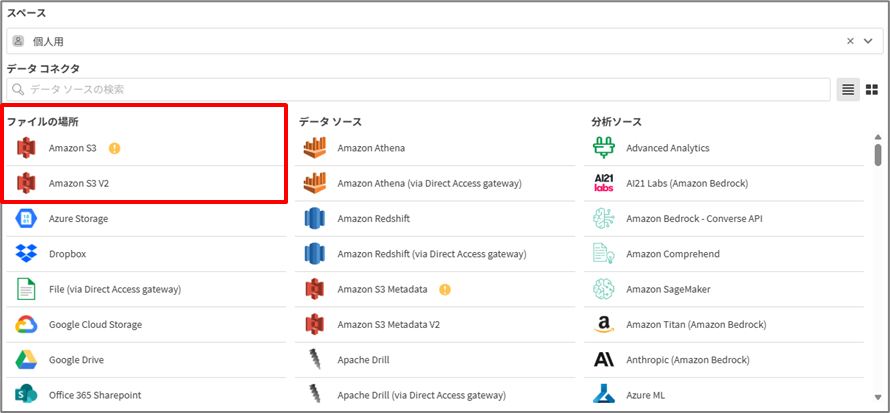
スペースを指定のうえ、ファイルの場所から『Amazon S3 V2』を選択し、接続情報を入力することで、指定したスペースに接続が新規に作成されます。
ここから、一番左のアイコン『データを選択』を選択し、接続したAmazon S3から取り込むファイルを選択することができ、ロード文が作成されます。

今回はtestフォルダにある『testdata_売上202404』というcsvデータを取り込み、売上というテーブル名をつけました。
ループ処理による複数ファイルの取り込み
次にtestフォルダにある各月の売上データファイル『testdata_売上202404』から『testdata_売上202412』までを一括で取り込むことを考えます。
Qlik senseではワイルドカード(*)を使えば、一定の規則性を持つ名前のファイルをまとめて取り込むことも可能です。
FROM [lib://data:DataFiles/testdata_売上2024*.csv](Qlik senseのdataスペースにある『testdata_売上2024』から始まるデータを読み込む場合)
ただし、ワイルドカードはAmazon S3 等の一部のクラウドサービスからデータを取り込む場合には使用できません。このため、フォルダからファイル名から取得し、それらを全て読み込むようにロード文をループさせるという処理が必要になります。
まずデータソースへの接続を作成します。
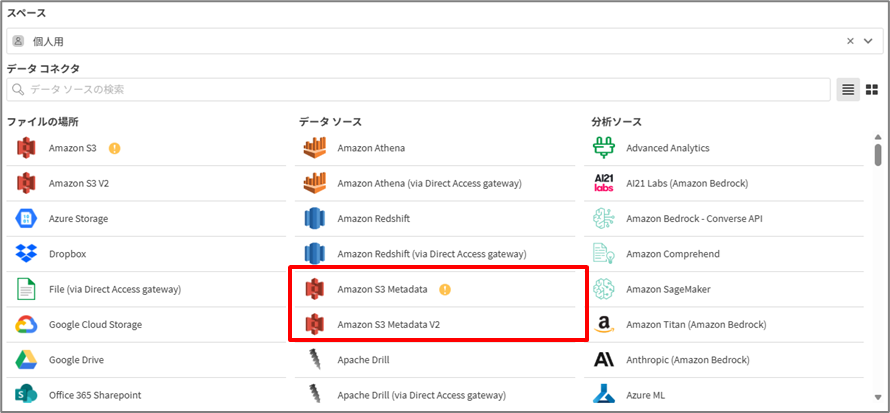
データソースへの接続が作成されたら、『データを接続』のアイコンよりAmazon S3に接続し、該当フォルダよりObject Key(ファイル名)を取得します。
ListObjectsにて、フォルダ名『test/』を入力し、フォルダを絞ります。
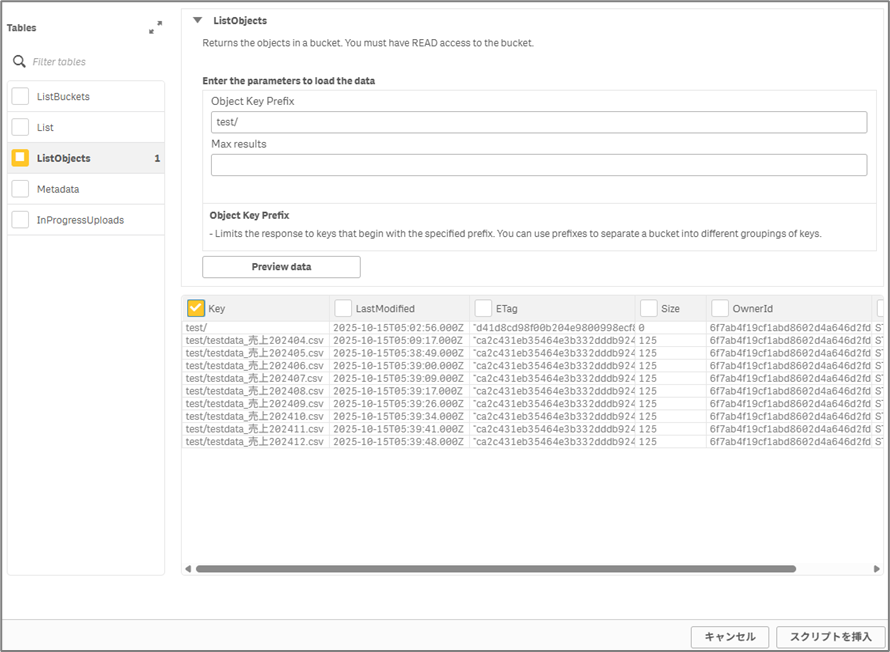
『スクリプトを挿入』を押すことでロード文が作成されます。
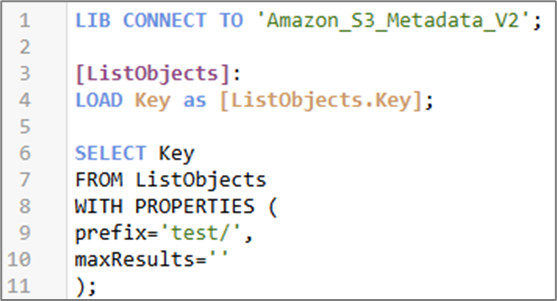
ここから、ループ処理を書いていきます。
// ファイル名を取得しfile_listを作成
// where句にて『売上2024』と入っているファイル名のみに絞り込む
// SubField関数にて'/'で区切り2番目の部分(『test/』以降の部分)をfile_nameとして取得する
file_list:
Load SubField(ListObjects.Key,'/',2) as file_name
Resident ListObjects
Where WildMatch(ListObjects.Key, '売上2024');
Drop Table ListObjects;
// NoOfRows関数にてfile_listの行数を取得
// ファイル名を変数の格納しループ処理で各ファイルLOADする
For i = 1 to NoOfRows('file_list')
Let vFile = FieldValue('file_name',$(i));
売上:
LOAD
売上日,
店舗ID,
顧客ID,
伝票番号,
商品コード,
数量,
売上金額
FROM [lib://Amazon_S3_V2/test/$(vFile)]
(txt, utf8, embedded labels, delimiter is ',', msq);
Next iこれにて、testフォルダにある『testdata_売上202404』から『testdata_売上202412』までのcsvデータを一つの売上テーブルとしてロードすることができました。








