こんにちは!Yokoです。
前回の記事では、QlikのRESTコネクタを使って、CSV形式ファイルのデータを取り込んでみましたが、文字コードの問題があることをお伝えしました。
その対策として、代替案があるのか…
考えてみましたが、ダウンロードするしかなかろうと今は思っています。
でも、手動でダウンロードするなんて悔しいですよね。
ということで、今回はQlik Automateを使用して、Webサイト上のファイルを自動的にダウンロードして、取り込むという方法で自動化にチャレンジしてみます。
作成手順
Qlik Cloudの契約があれば、自動化ツール”Qlik Automate“は追加料金なしで利用できます。
Qlik Automateでは様々なコネクタがある上、ワークフローを構築するための便利な部品が最初からありますので、これ1本で、サイトにアクセスして、ファイルをダウンロードし、Qlikのリロード処理までの一連の流れを完全自動化できます。
今回は以下の手順でワークフローを作成していきます。
- ダウンロードしたいファイルのリストを変数に格納する
- 変数に格納したファイルのリストから対象のファイル名を順番に取得する
- Amazon S3のディレクトリに該当のファイルがあるかをチェックし、あれば削除する
- Amazon S3に格納するファイルにWebサイトから取得したファイルを書き込んで保存する
- Qlikのリロード処理を実行する
取得するWebサイト上のファイル
今回は文部科学省の全国の学校コードのリストを取得します。
サイトはこちらです。
文部科学省に届け出のある幼稚園、小学校、高校、専門学校、大学(公立・私立を問わず)には「学校コード」というコードが振られていまして、通称「文科省コード」というのですが、これで一意に識別できるようになっています。
このリストは毎年更新されていて、実はファイル名も変わってしまうので、最適ではないのだけれど、そこは目をつぶって下さい(たまたま使う用途があっただけです😅)。
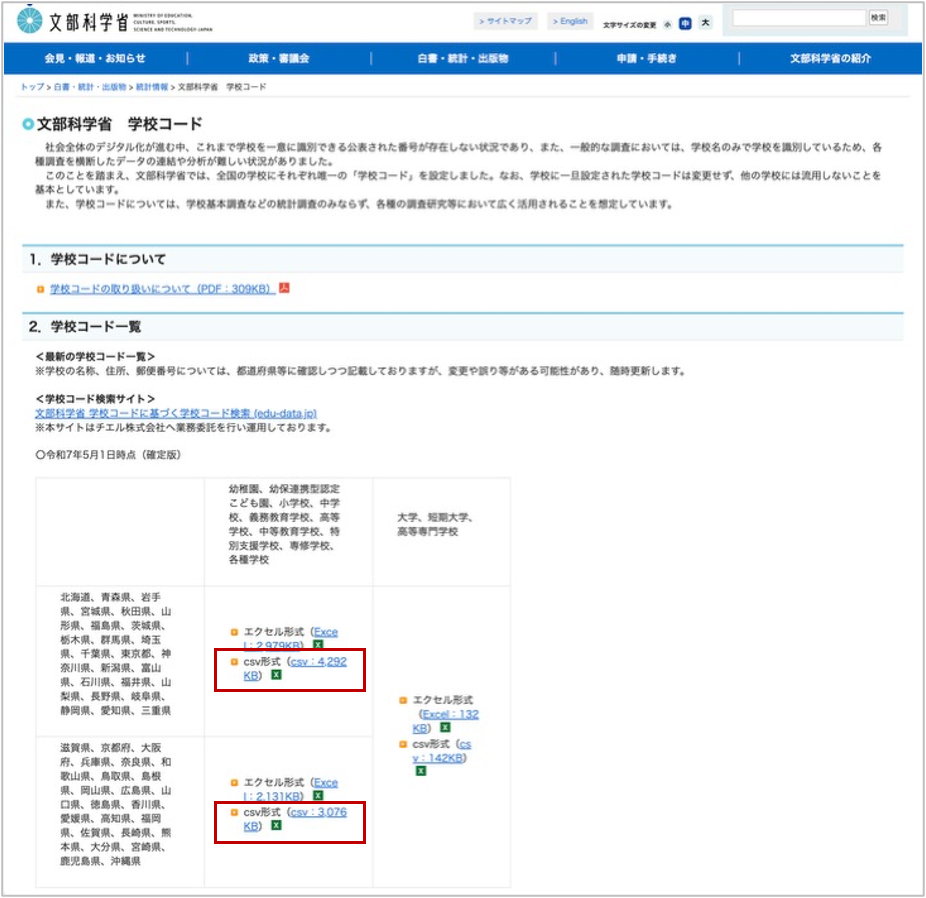
サイトのリンクからURLを取得します。対象を2つです。
| URL | ファイル名 |
|---|---|
| https://www.mext.go.jp/content/20251226-mxt_chousa01-000011635_2.csv | 20251226-mxt_chousa01-000011635_2.csv |
| https://www.mext.go.jp/content/20251226-mxt_chousa01-000011635_4.csv | 20251226-mxt_chousa01-000011635_4.csv |
以下、手順を追って解説していきます。
1. ダウンロードしたいファイルのリストを変数に格納する
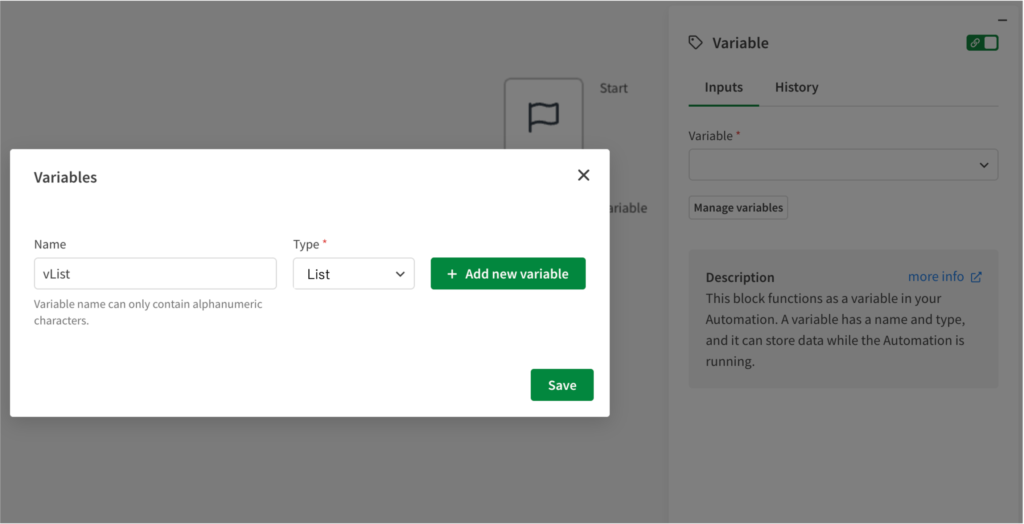
Variableブロックで、vList(list)を定義し、vListにファイル名を2つ格納しておきます。
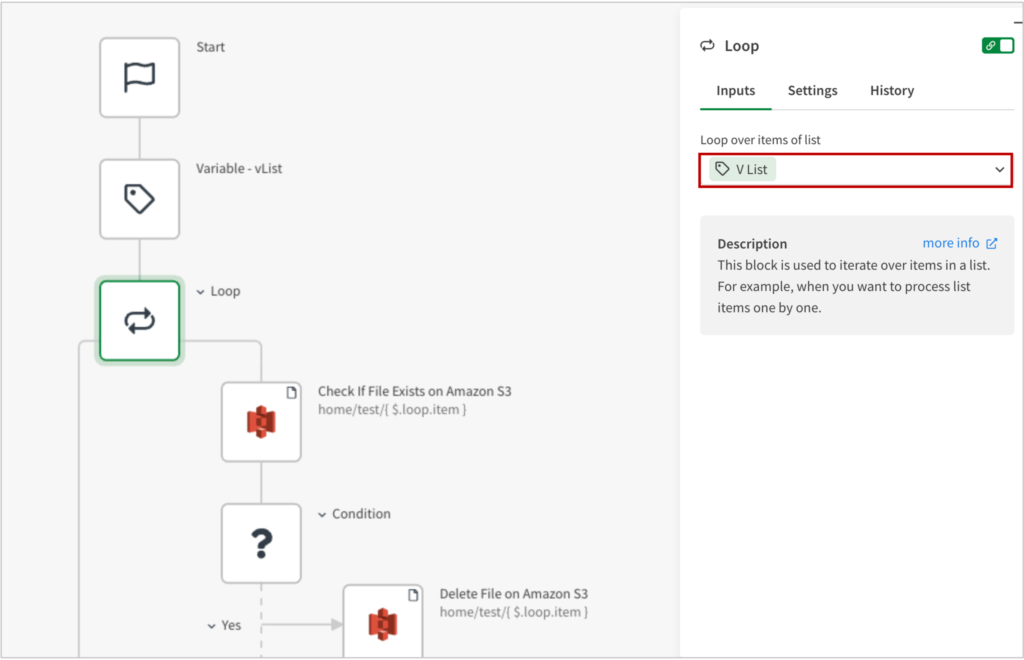
2. 変数に格納したファイルのリストから対象のファイル名を順番に取得する
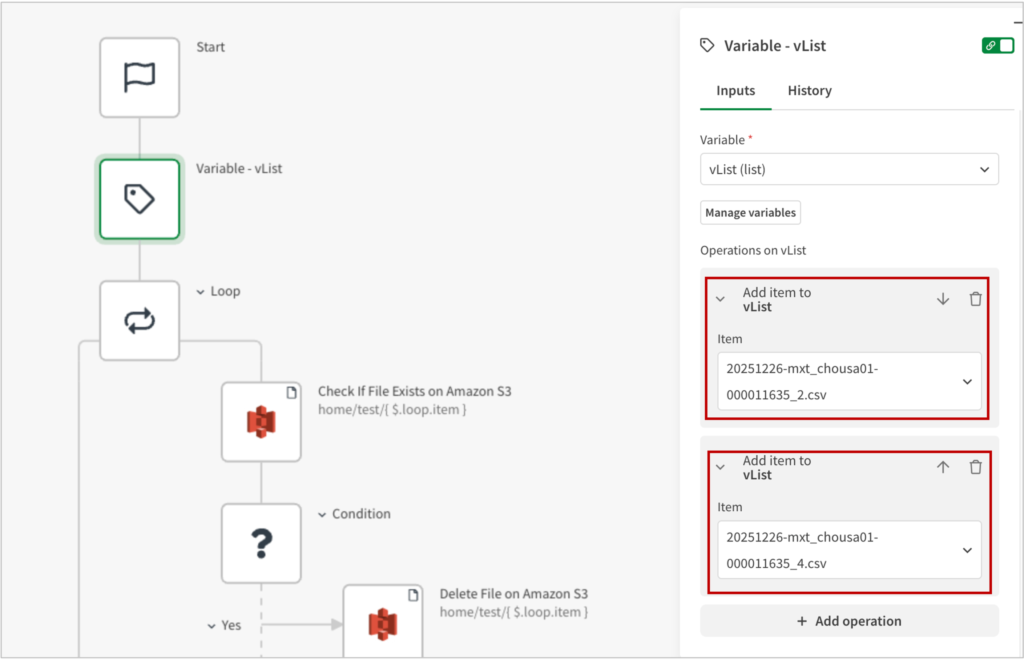
Loopブロックを追加し、Loop over items of listに上記のvListを指定します。これで、順番に変数の値を取得できるようになります。
ここでは、1回目のループで1つめのファイル名、2回めのループで2つめのファイル名が取得されます。
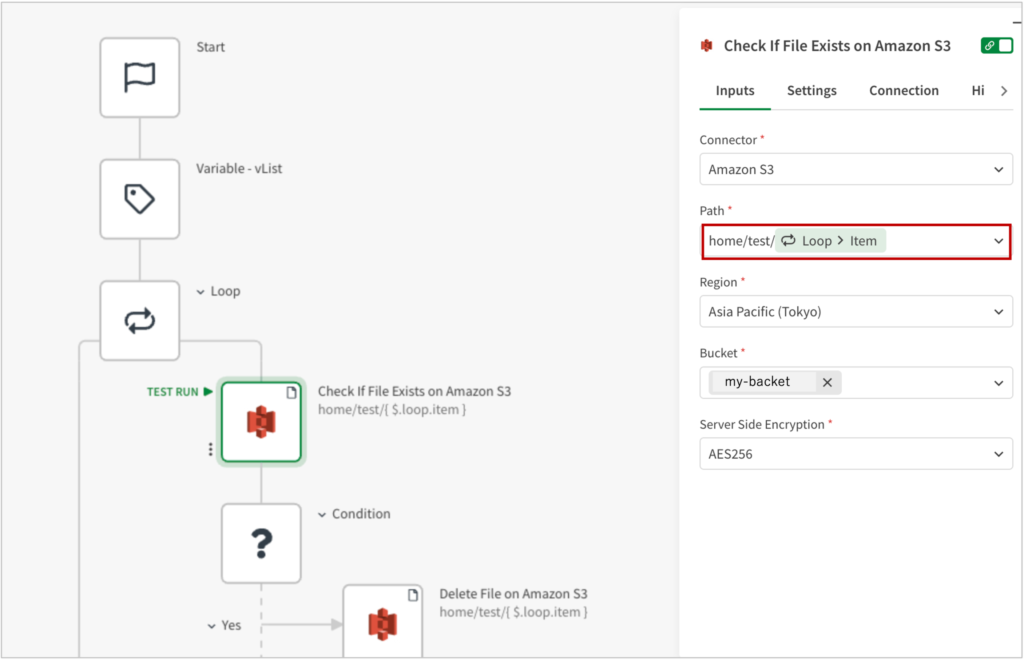
3. Amazon S3のディレクトリに該当のファイルがあるかをチェックし、あれば削除する
Amazon S3の[Check If File Exists on Amazon S3]ブロックを設定します。
今回はhome/testディレクトリにファイルがあるかを確認しますので、Pathに、home/test/に続けて、上記の[Loop > item]を追加します。
Conditionブロックを追加し、上記の[Check If File Exists on Amazon S3]が、”is true”という条件分岐とします。
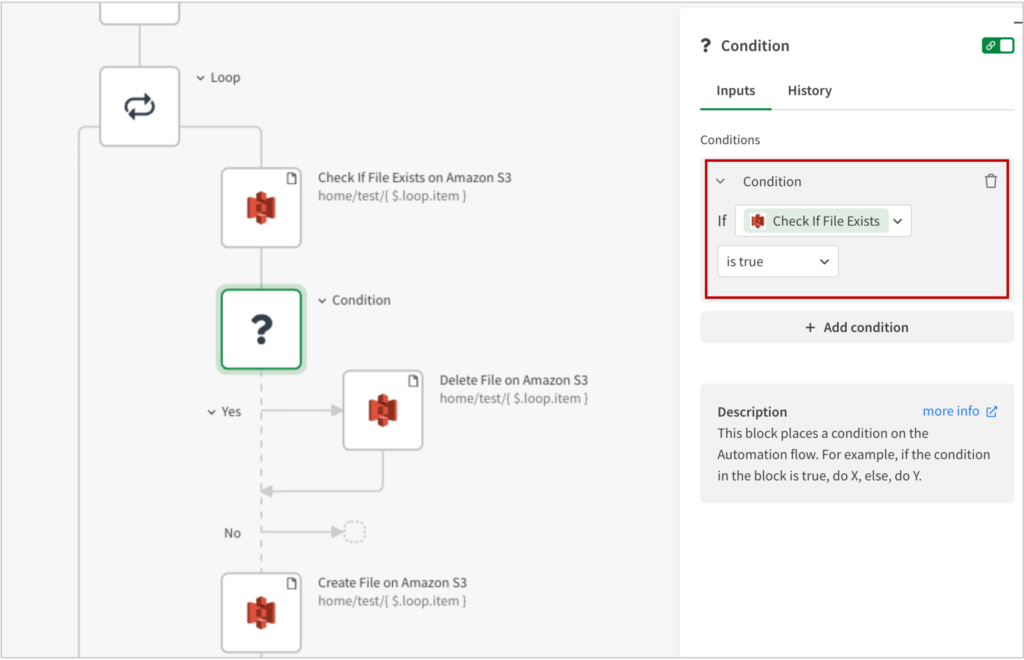
Conditionの結果がtrueの時は”Yes”に進み、home/test/[Loop > item]を削除します。
なぜ、このように処理するのかというと、上書きができないため、ファイルがあれば削除しておき、ファイルを追加するという処理の流れにする必要があるからです。
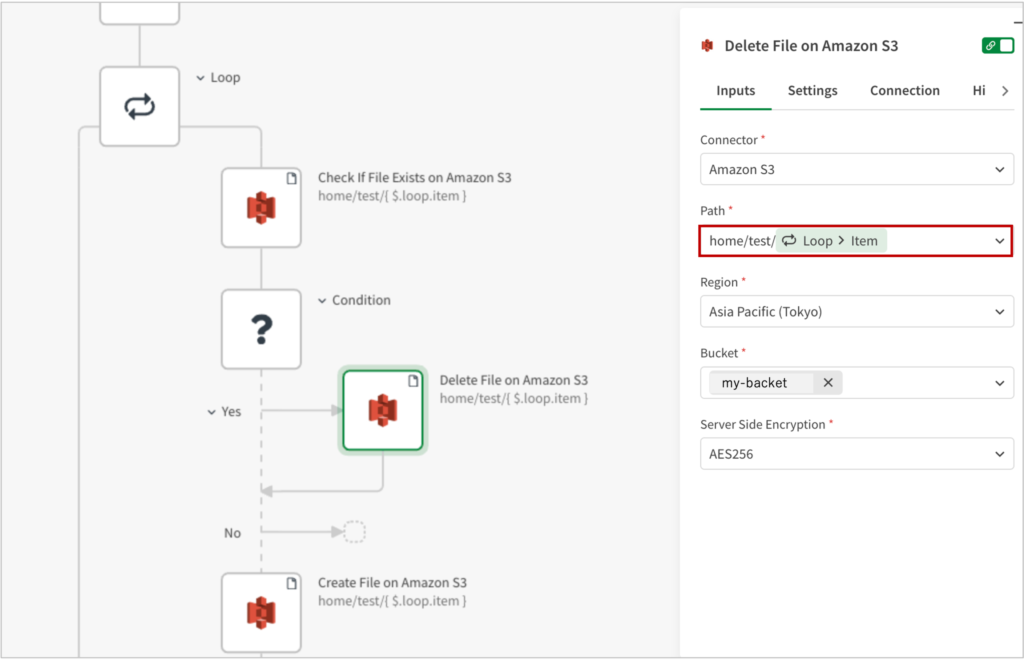
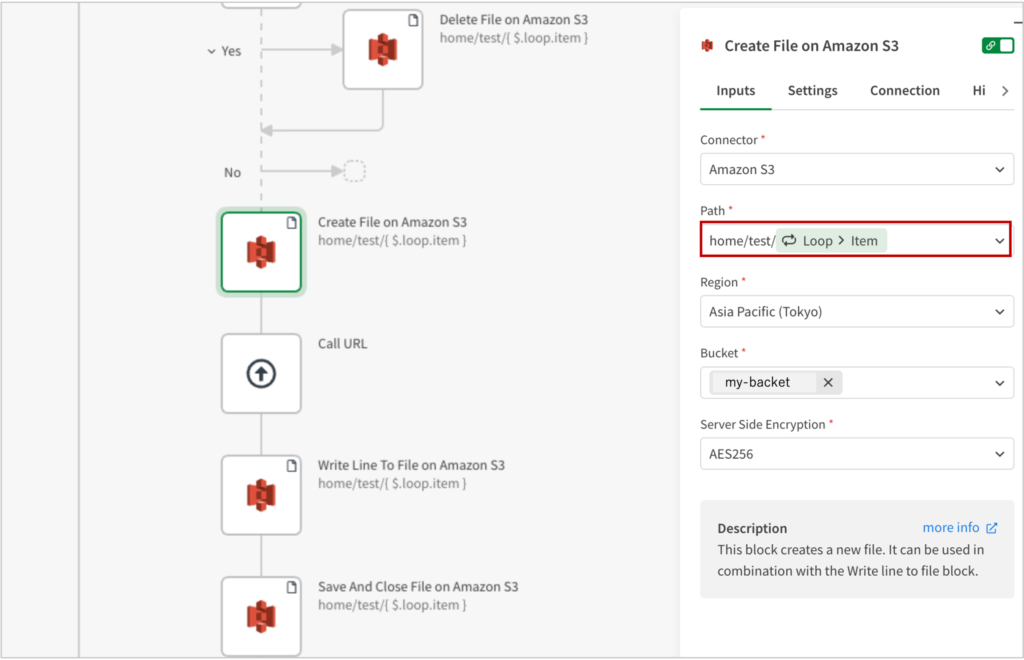
4. Amazon S3に格納するファイルにWebサイトから取得したファイルを書き込んで保存する
Amazon S3の[Create File on Amazon S3]ブロックを追加し、Pathに、home/test/Loop > itemと設定します。
この状態で、空のファイルが出来上がります。
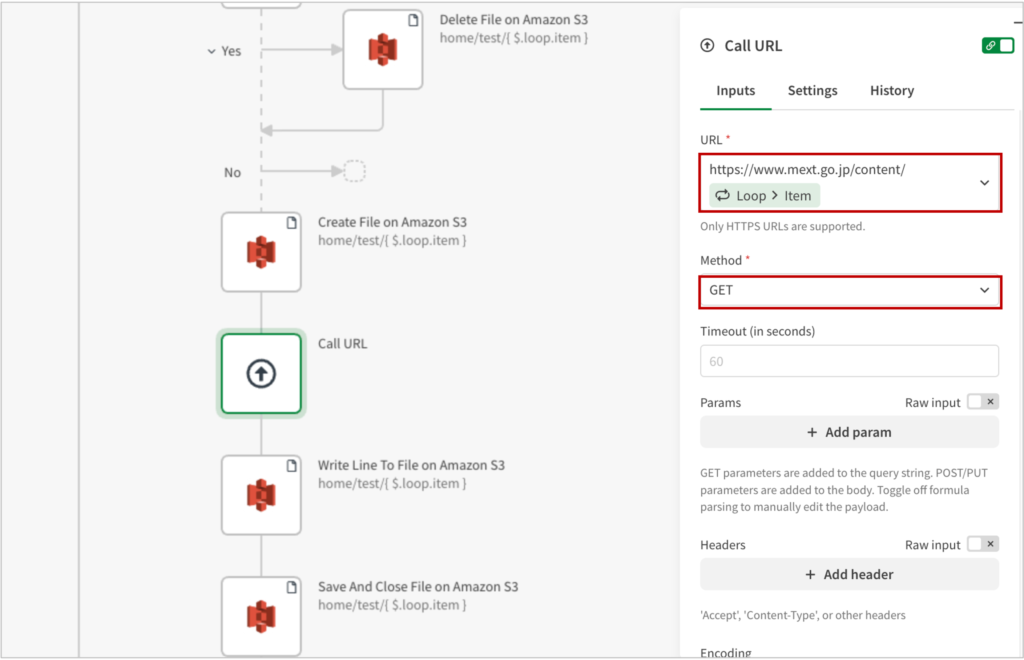
Call URLブロックを追加します。
URLには、ファイル名を除くURL(ここではhttps://www.mext.go.jp/content/)に続けて、[Loop > item]を設定します。Methodは”Get“とし、あとはデフォルト設定で構いません。
これで、Webサイトのファイルを取得できます。
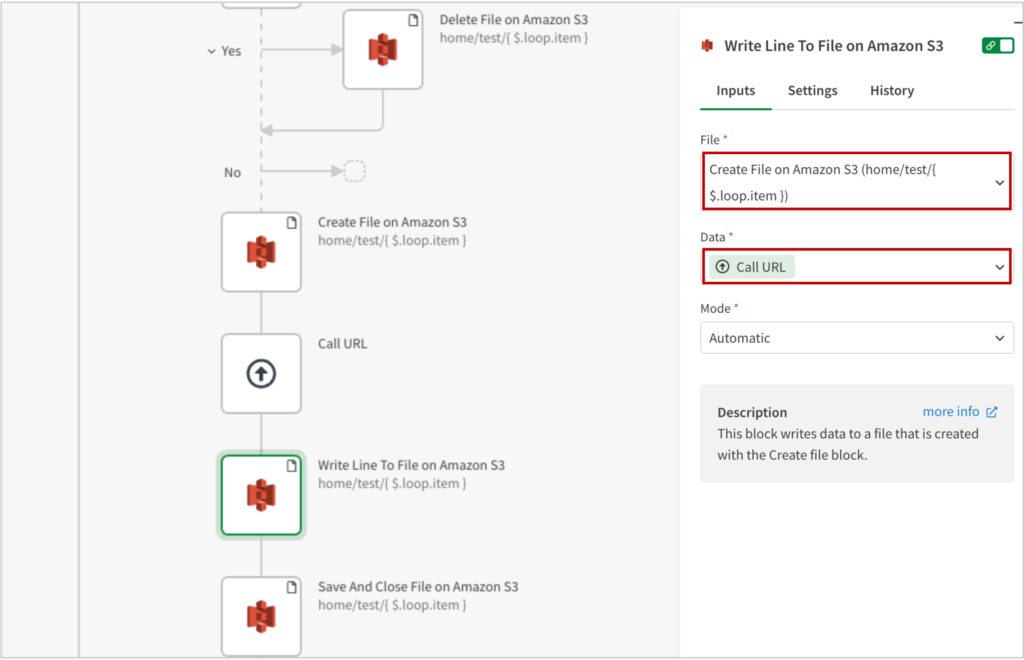
Amazon S3の[Write Line To File on Amazon S3]ブロックを追加します。
ここではFileに[Create File on Amazon S3]で作成したファイルを指定します。
そして、Dataには[Call URL]を指定すれば、Call URLで取得したデータを流し込むことができます。
Write Line…というブロック名からすると、1行ずつ書き込むように思えますが、コンテンツそのものを書き込むことができるんです。
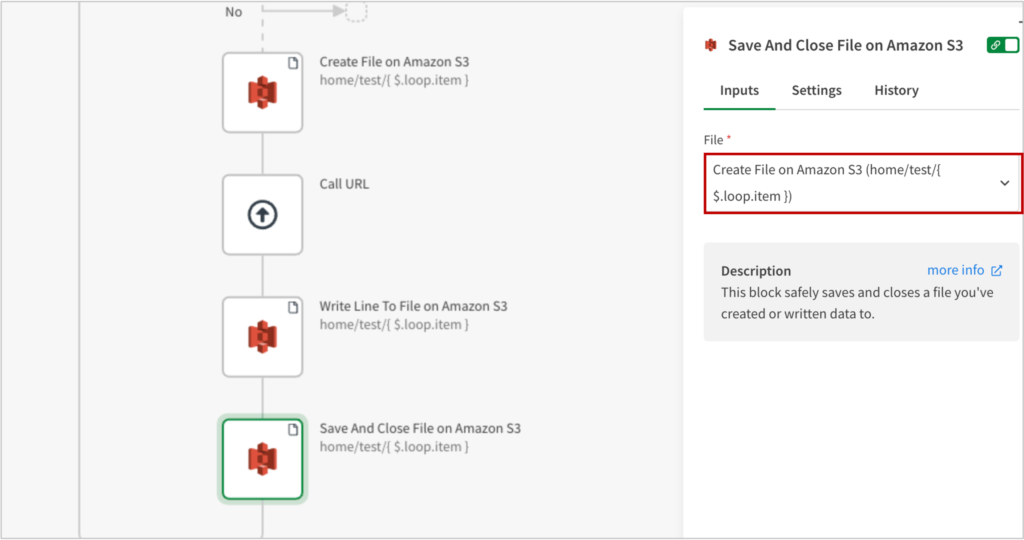
書き込みが終わったら[Save and Close File on Amazon S3]で保存します。
これがLoopの最後の処理で、1つめのファイルの保存が終わったら、続けて2つめのファイルも同様に保存するように処理が走ります。
5. Qlikのリロード処理を実行する
Loop処理が終わったら、Qlik Cloud Serviceの[Do Reload]ブロックを追加し、リロードするアプリ名を指定します。
これで、Qlik Senseのリロードが実行されます。
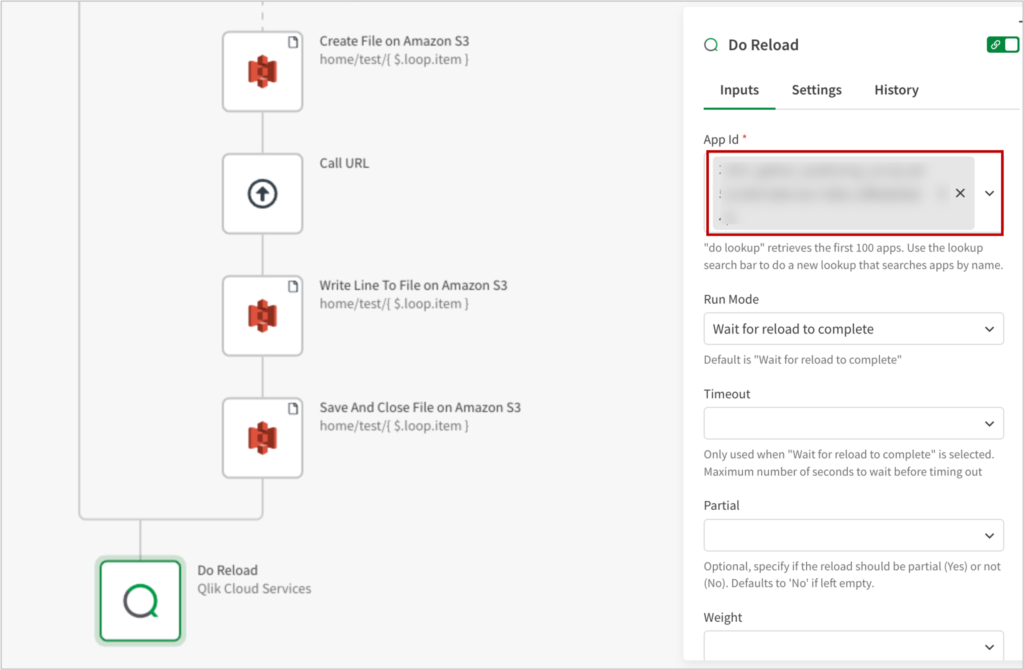
以上で、Webサイトのファイルをダウンロードした後に、自動的にQlik Senseがリロードされる一連の処理が実行できるようになりました。
あとは一番最初の[Start]ブロックでスケジュールを設定すれば、定期的に自動実行されるようになります。
まとめ
以上、Qlik AutomateでWebサイトからファイルをダウンロードして、Qlik Senseのリロードを実行するワークフローができました。
この方法であれば、ファイル形式や文字コードの変換は、Qlik Senseに任せてしまえるので、万能ですよね。
どう使うかは、あなたしだいです。
ではまた!